Casual Tips About How To Build Web Crawler

Build A Crawler To Extract Web Data In 10 Mins | By Octoparse Dataseries Medium
Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse
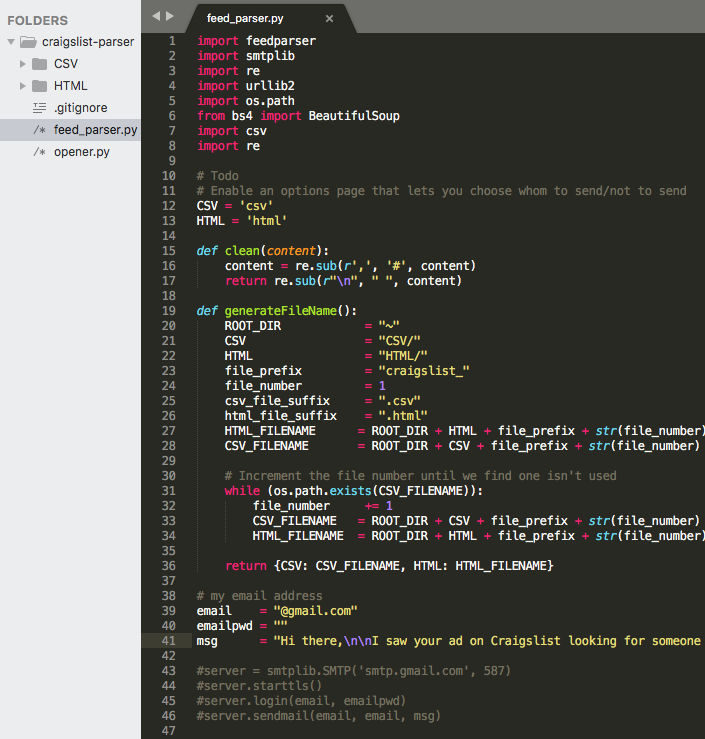
How I Automated My Job Search By Building A Web Crawler From Scratch

Step-by-step Guide To Build A Web Crawler For Beginners | Octoparse
Web Crawling With Python | Scrapingbee
You might need to build a web crawler in one of these two scenarios:
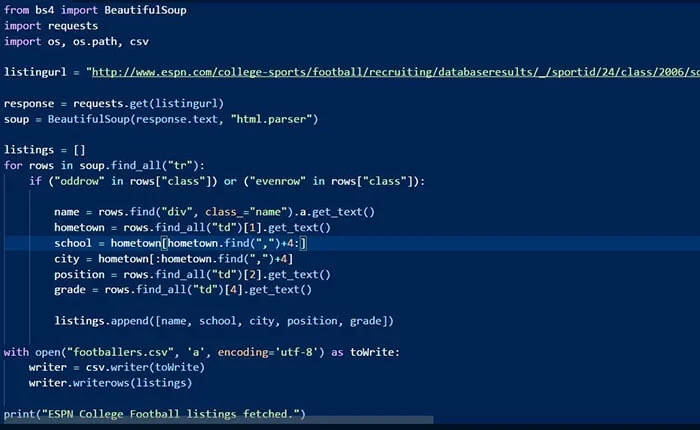
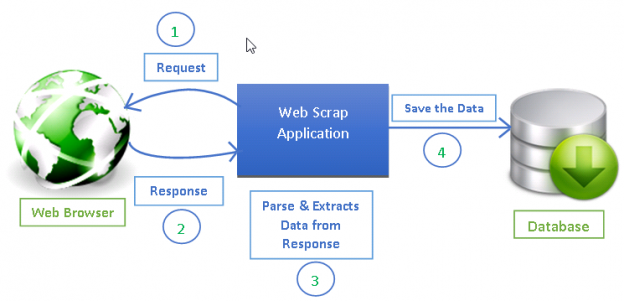
How to build web crawler. What you’ll need typically, crawling web data involves creating a script that sends. Install the proxycrawl module through the terminal by executing the following command: In this article, we’ll walk you through the process of building a web crawler using java and proxycrawl.
Provide users with relevant and valid content. Pay attention to the purple box, you will notice there is an addition of page=2 in the request url. Now, to the tutorial’s core, we will build a web crawler that uses the bfs algorithm to traverse web pages.
Trandoshan is divided in 4 principal processes: This is provided by a seed. The process responsible of crawling pages:
Best seo wordpress themes for building websites that rank. A web crawler can be written in java, c#, php, python, or even javascript. Add one or several urls to be visited.
The main thing to look for in the best wordpress themes in terms of seo is how lightweight it is and how well. Robots( web crawlers) need to know that a website exists to come and analyze it. In this video we'll be learning about how web crawlers work and we'll be covering the different types of link that our web crawler will have to be able to de.
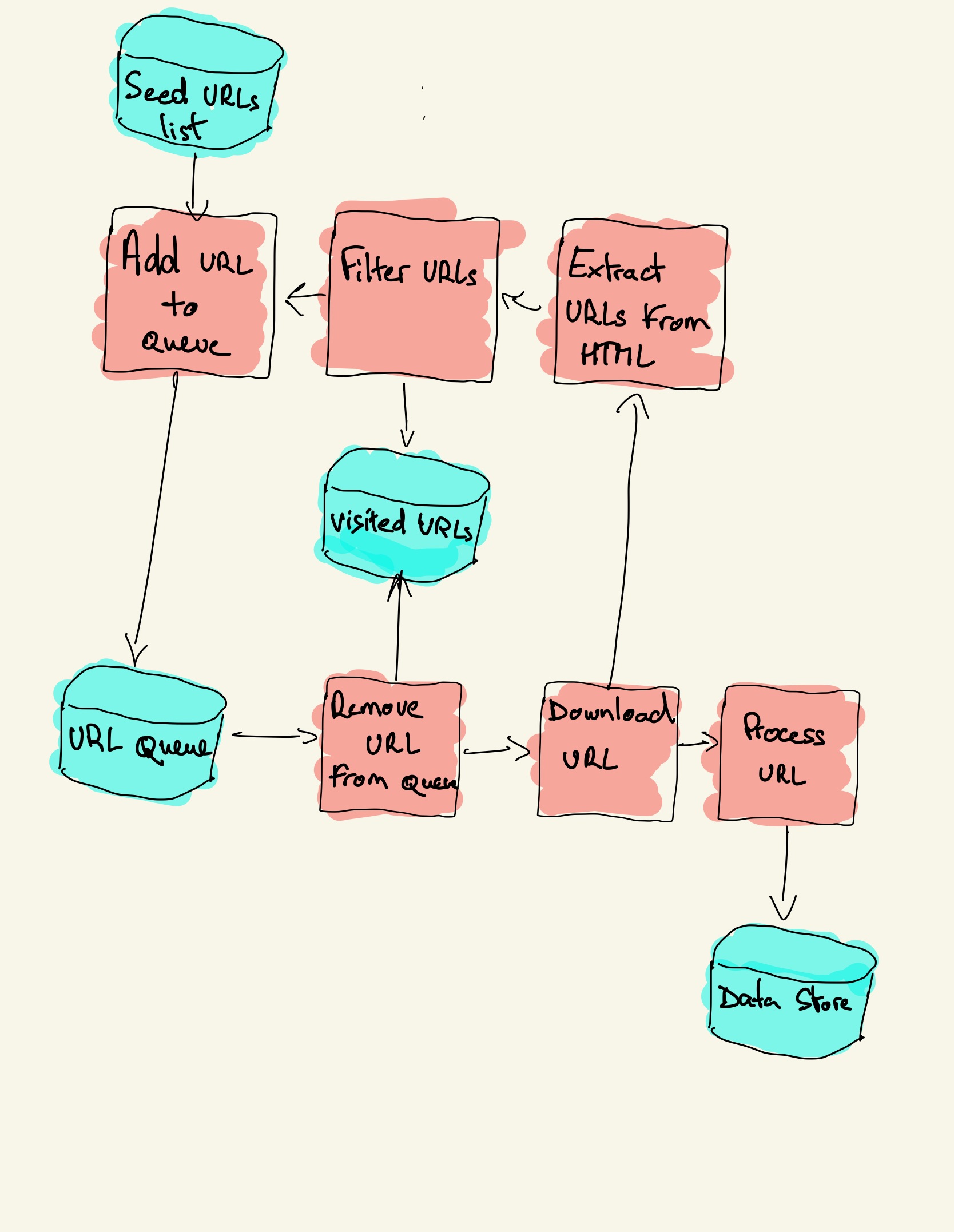
The first thing to do when configuring the request is to set the url to crawl. Open node.js and create a new project. The diagram below outlines the logical flow of a web crawler:
All you have to do is provide the url of the site you. Here are the basic steps to build a crawler: This is not easy since many factors need to be taken into consideration, like how to better leverage the.
Then we will build a simple web crawler from scratch in python using two libraries: The crawler will begin from a source url that visits every url. It read urls to crawl from nats (message identified by subject todourls),.
Pop a link from the urls to be visited and add it to the visited urls thread. A web data extraction service provider, like us at promptcloud, takes over the entire build and execution process for you. First, click on the page number 2, and then view on the right panel.
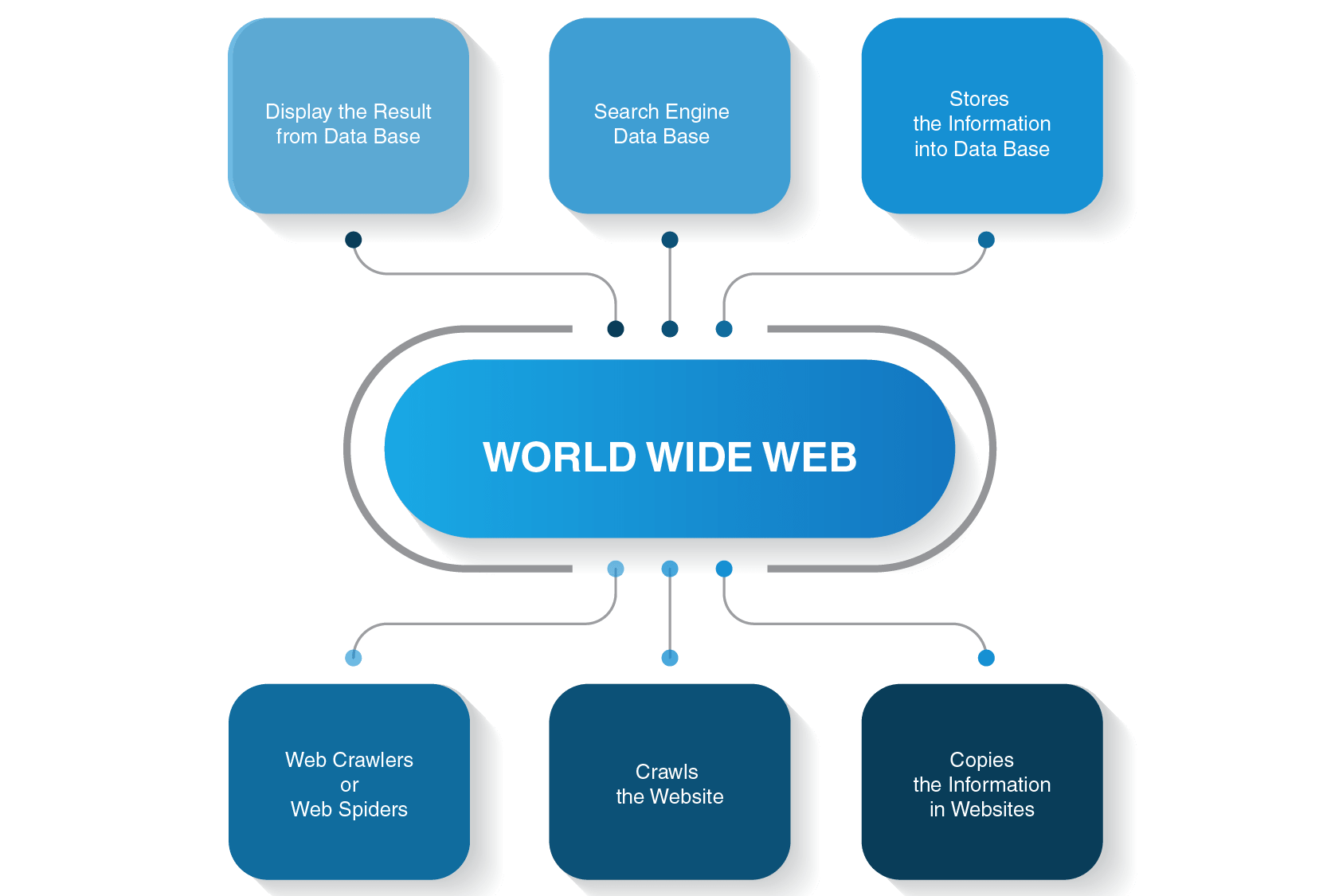
Create a new.js file where we will write. Create a copy of all the visited pages for. To replicate the search function as in the case of a search engine, a web crawler helps:

Make Your Own Web Crawler - Part 1 The Basics Youtube

Web Crawling And Scraping In Python | By Muhammad Abdulmoiz Codeburst
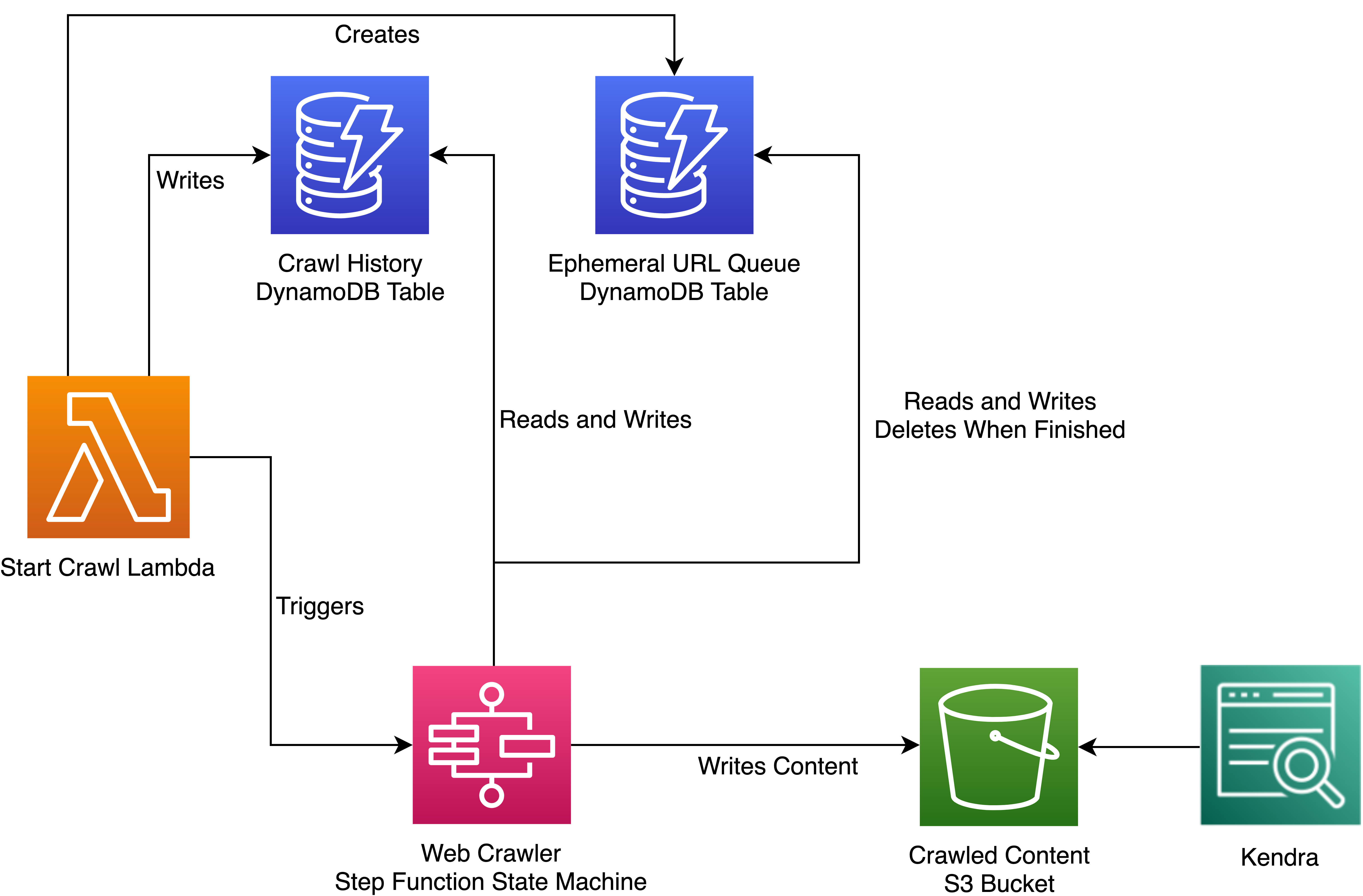
Scaling Up A Serverless Web Crawler And Search Engine | Aws Architecture Blog

Web Crawler - Wikipedia

How To Build A Web Crawler In Python From Scratch - Datahut

Python Programming Tutorial - 25 How To Build A Web Crawler (1/3) Youtube

How To Build A Serverless Web Crawler | Cloud Guru

How To Build A Simple Web Crawler | By Low Wei Hong Towards Data Science
Scrapy Python: How To Make Web Crawler In Python | Datacamp

5 Steps To Build A Faster Web Crawler | Better Programming

How To Build A Web Crawler? - Scraping-bot.io
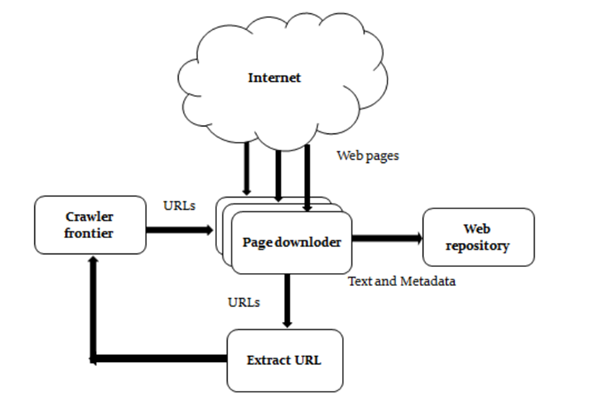
From 0 To 1: How Build A Web Crawler Scratch By Python. Part I. | Lena Li Medium